Elixir 解析XML的几个坑
在Elixir 1.0.2中解析XML文档的时候,最开始是参考的这个视频, 总之在Google的搜索结果中掉进了无数多个坑后,终于爬出来了.
创建一个项目, 本文所述所有内容都是在文件test/xml_parsing_test.exs文件中完成, 并通过mix test执行测试用例:
root@c87c9967219c:~# mix new xml_parsing
* creating README.md
* creating .gitignore
* creating mix.exs
* creating config
* creating config/config.exs
* creating lib
* creating lib/xml_parsing.ex
* creating test
* creating test/test_helper.exs
* creating test/xml_parsing_test.exs
Your mix project was created successfully.
You can use mix to compile it, test it, and more:
cd xml_parsing
mix test
Run `mix help` for more commands.
把我拉出来的是下面这篇Wiki, 视频中的代码有几个问题:
defrecord关键字废弃了,必须用Record.defrecordRecord.defrecord不能定义在模块的外面了,必须定义在模块内部, 比如:1
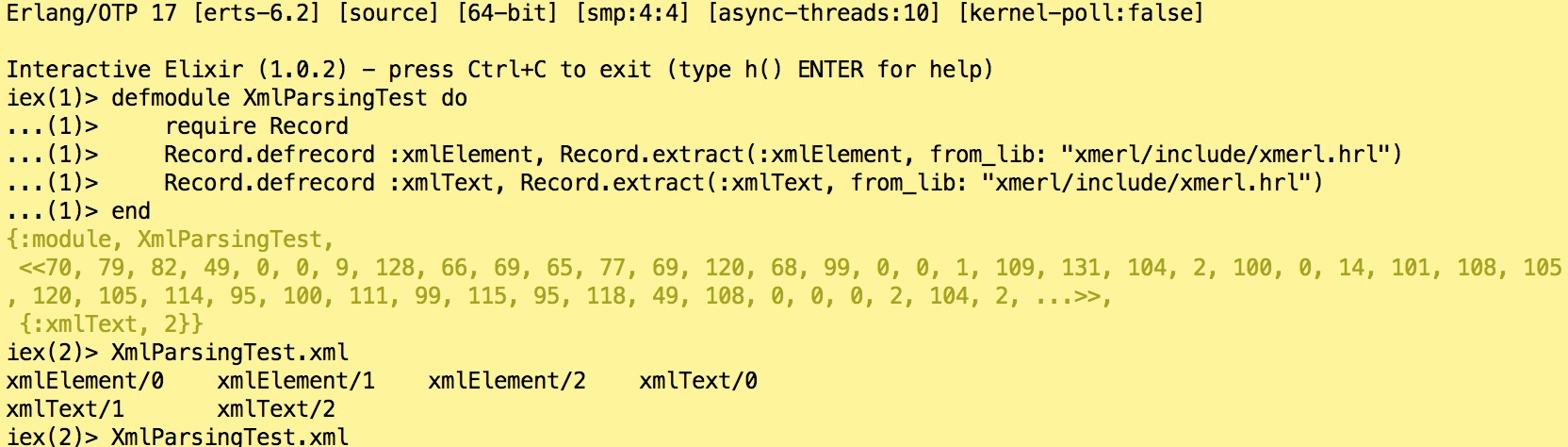
defmodule XmlParsingTest do use ExUnit.Case require Record Record.defrecord :xmlElement, Record.extract(:xmlElement, from_lib: "xmerl/include/xmerl.hrl") Record.defrecord :xmlText, Record.extract(:xmlText, from_lib: "xmerl/include/xmerl.hrl") ... end
获取节点值的方式变了
1 | test "Test parsing xml document OLD" do {xml, _rest} = :xmerl_scan.string(:binary.bin_to_list(sample_xml)) [ title_element ] = Enum.first(:xmerl_xpath.string('/blog/title', xml)).value [ title_text ] = title_element.content title = title_text.value assert title == 'Using xmerl module to parse xml document in elixir' end # 对比上下两个测试方法的区别 test "Test parsing xml document NEW" do {document, _} = :xmerl_scan.string(String.to_char_list(sample_xml)) [element] = :xmerl_xpath.string('/blog/title/text()', document) assert xmlText(element, :value) == 'Using xmerl module to parse xml document in elixir' end |
对比上面的代码, 我们通过Record.defrecord定义记录, 该记录是从Erlang的xmerl库中提取的(调用Record.extract), 该记录将作为测试模块的一个函数,我们可以通过下面的方法验证:
运行iex进入Elixir Shell, 并声明模块:
1 | test "Test parsing xml document" do # 解析XML文档 {document, _} = :xmerl_scan.string(String.to_char_list(sample_xml)) # XPATH查询 [element] = :xmerl_xpath.string('/blog/title/text()', document) # 断言 assert xmlText(element, :value) == 'Using xmerl module to parse xml document in elixir' end |
完整的代码
https://gist.github.com/94ce9976fc52e04e572a
完整的项目代码
https://github.com/developerworks/xml_parsing
参考资料
- ELIXIR AND XML
http://erlangcentral.org/wiki/index.php?title=Elixir_and_XML - 028: Parsing XML
http://elixirsips.com/episodes/028_parsing_xml.html - 常用的XML文档解析模块
https://github.com/h4cc/awesome-elixir#xml







